
はじめに
論文紹介
以下の論文を読み要点をまとめます。

本論文は要約タスクにおいて、レスポンスの後半にハルシネーションが発生しやすいということを示した論文です。
また、自分の性格として論文の中のすべてに目を通したいため、論文のすべてを日本語訳した後に得られた知見をまとめることとします。
動機
マルチエージェントシステムのユースケースでは、各エージェントの出力結果を最後に要約することがあります。
業務中、要約のふるまいによって精度に影響が出てくることに悩まされていたため、その解決策が見つかるのではと思い当該論文を熟読してみます。
日本語訳
表題
ロングレスポンス生成の最後に幻覚を見る:長文文書要約のケーススタディ
要旨
大規模言語モデル(LLM)は、要約のようなタスクを含むテキスト生成能力を大幅に進展させ、しばしば一貫性があり流暢な出力を生成します。しかし、生成された幻覚(ハルシネーション)によるソース資料への忠実度は依然として重要な課題であり、この問題の検出と低減に関する広範な研究が行われています。しかし、生成されたテキスト内での幻覚の位置分布に関する研究は少なく、特に長い出力においては注目されていません。本研究では、LLMを基にした長文生成において幻覚がどこで発生するかを調査し、長文要約を主要な事例研究として扱います。長い文脈を意識した長いレスポンス生成という困難な設定に焦点を当て、私たちは一貫して懸念すべき現象を発見しました。それは、幻覚が生成された長いレスポンスの後半部分に不均衡に集中する傾向があるということです。このバイアスを理解するために、長いシーケンスにおける注意の動態とデコーディングに関連する潜在的な要因を探ります。さらに、この位置的幻覚を軽減する方法を調査し、特に長い出力の結論部分での忠実度を向上させることを目指します。
1 導入
最近の大規模言語モデル(LLM)の進展により、テキスト要約などのタスクにおいて、人間に似た言語生成の限界が押し広げられました(Chang et al., 2024b)。その規模と洗練された学習により、LLMは一貫性と流暢さを備えた要約を生成し、人間レベルの品質に近づいています(Roit et al., 2023; Song et al., 2025)。この能力により、大量のテキストとのインタラクション方法が変革され、情報へのアクセスが容易になっています(Achiam et al., 2023; Grattafiori et al., 2024; Team et al., 2024; GLM et al., 2024)。
LLMが進化し続ける中で、短い形式から長い形式への生成のパラダイムシフトが現れています。このシフトは、拡張されたコンテキストを処理する能力によって可能になりました(Wu et al., 2025a)。長い出力生成は、複雑な推論タスク(例えば、長いChain-of-Thoughtプロンプティングや言語エージェント)にとって重要であり、一貫性のあるコンテキストに基づいた長いレスポンスが必要です(Jaech et al., 2024; Sumers et al., 2024; Wang et al., 2024)。最近のベンチマークでは、長い生成能力を評価していますが(Wu et al., 2025b; Ye et al., 2025)、これらはしばしばコンテキストに基づいた忠実度を欠いており、長形式生成における重要な側面であるコンテキストを意識した忠実度を見過ごしています。
LLMが直面している継続的かつ重要な課題の一つは、幻覚(ハルシネーション)現象です。これは生成されたコンテンツが入力コンテキストに忠実でない、またはサポートされていない場合に発生します(Huang et al., 2025)。これまでの広範な研究は幻覚の検出と軽減に焦点を当ててきましたが、大きな制約は、生成されたシーケンス内の事実誤りの空間的分布に関する研究が不足していることです。関連する研究では、モデルが入力コンテキストを処理する際の位置的バイアス、特に「Lost in the Middle」現象が探求されています(Liu et al., 2024b; Wan et al., 2025)。しかし、生成された出力内での誤りの分布を理解すること、特に長いコンテキストからの長いレスポンスにおける誤りの分布を理解することは、効果的な診断と軽減にとって同様に重要です。
この重要な研究ギャップに動機づけられて、私たちの研究は長いレスポンス生成中の幻覚の空間的分布について初めての専用調査を提供します。特に、長い文書要約という困難な設定でこの現象を調べます。従来の研究が主に長い入力コンテキストや短い出力に焦点を当てているのに対して(Tang et al., 2023; Zhang et al., 2024a; Bishop et al., 2024)、私たちは長いコンテキストを意識した長いレスポンス生成を扱います。この生成は、長い入力を処理し、長大な出力シーケンス全体にわたって忠実度を維持することが求められます。具体的には、以下の核心的な研究課題を設定しました:長形式生成タスク(例えば文書要約)において幻覚はどのくらい頻繁に発生し、発生する場合、出力のどの部分で最も多く発生するか?
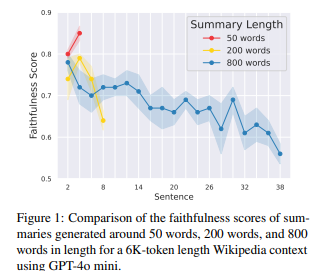
私たちの分析は驚くべきかつ懸念すべき傾向を明らかにしました:幻覚は生成されたテキストの最後の部分に集中する傾向があり、これを「最後で幻覚が発生する」と呼びます。図1に示すように、忠実度は長い要約(例えば800語)では最後に向かって大幅に低下します。均等分布の期待に反して、この明確な位置的バイアスは、LLMが長いテキストを生成する際の重要な脆弱性を示しています。この現象とその影響を体系的に分析するために、私たちの研究は次の3つの核心的な質問に取り組みます:
RQ1. 幻覚は最も頻繁にどこで発生するか?(§3)
RQ2. 幻覚が最後に集中する要因は何か?(§4)
RQ3. 最後の部分での幻覚をどのように軽減できるか?(§5)
これらの質問に答えるために、まず幻覚の位置的分布を実証的に特徴付けます(RQ1)。その後、この現象の原因となる可能性のある要因を生成過程に関連して探ります(RQ2)。最後に、後半部分の幻覚に対処するための軽減戦略を提案し評価します(RQ3)。私たちの発見は、誤りの空間的次元を考慮する必要性を強調し、より堅牢な長形式生成システムの開発に向けた洞察を提供します。
私たちの貢献は次のように要約できます:
- 長いレスポンス生成、特に長文書要約における「最後で幻覚が発生する」現象の最初の実証的特徴付けを提供します。
- この後半部分での幻覚に寄与する可能性のある要因についての初期の洞察と分析を提供します。
- 位置的幻覚に特化した軽減戦略を調査します。
図1
2 要約の作成
このセクションでは、私たちの研究で分析された要約を生成するために使用した実験の設定について説明します。私たちはLLMに対して、元の文書から要約を生成するように指示し、コンテキストの長さと出力の長さの両方を変化させました。
2.1 入力コンテキストの長さ
入力長の影響を分析するために、私たちはさまざまなコンテキスト長にわたってモデルの性能を評価します。コンテキスト長は約1Kトークンから16Kトークンまで変化させます。実験で使用した具体的なコンテキスト長は1Kから8Kトークンまでで、1Kトークンごとの増分で行います。
2.2 出力長カテゴリー
「最後で幻覚が発生する」現象を研究するために、出力長に対して2つのカテゴリを定義します:
- ショートアウトプット:長さが100語から200語の要約
- ロングアウトプット:入力コンテキスト長の最大30%の長さの要約
この区別により、標準的な要約長と著しく長く生成されたレスポンスにおける幻覚のパターンを比較することができます。ショートアウトプットとロングアウトプットの両方のカテゴリを含めることで、生成された要約の長さが増加するにつれて、幻覚の位置的バイアスがどのように現れ、潜在的にどれほど深刻になるかを体系的に分析することを目的としています。詳細については、付録Aをご参照ください。
2.3 全体的な忠実さ
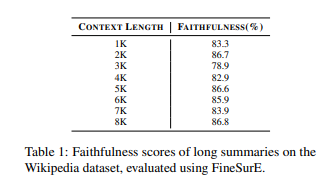
詳細な位置分析を行う前に、生成された長い要約における忠実度のレベルを一般的に理解するため、まず全体的な忠実度スコアを報告します。表1に示すように、私たちはLlama3.1-8B-Instruct(Grattafiori et al., 2024)を使用して、Wikipediaデータセットで生成された長い要約の全体的な忠実度を報告します。コンテキスト長は1Kから8Kまでの範囲です。全体的な忠実度スコアの計算には、GPT-4(Achiam et al., 2023)を使用したFineSurE(Song et al., 2024)フレームワークを採用しています。FineSurEは、各文をソースコンテキストと比較し、一貫性のない部分が検出された場合に特定の誤りの種類を識別することで要約を評価します。
結果に示されているように、全体的なパフォーマンスは、元のFineSurE論文で報告されたCNNDM(Hermann et al., 2015)データセットでの結果と一致しており、Llama3-70B-Instructモデルによって生成された要約の忠実度は85.5%と報告されています。これを基に、私たちはセクション3で要約の忠実度についてより詳細な評価を行います。この評価には、出力の異なる部分で事実の一貫性がどのように変化するかを調べる位置的分析が含まれています。
表1:
3 幻覚はどこでよく起こるのか?
このセクションでは、長文書要約において幻覚が最も頻繁に発生する場所を実証的に調査します。異なるモデル、データセット、出力位置における忠実度を調べることで、事実誤りの位置的分布を分析します。
3.1 実験セットアップ
モデル
私たちは、いくつかの最先端の大規模言語モデルを使用して実験を行い、得られた結果が特定のモデルに依存しないことを確認します。評価対象となるモデルには、Llama3.1-8B-Instruct(Grattafiori et al., 2024)、Mistral-7B-Instruct-v0.3(Albert Q. Jiang et al., 2023)、Qwen2.5-7B-Instruct(Yang et al., 2024a)、およびGPT-4o mini(Achiam et al., 2023)が含まれます。
データセット
この現象がドメイン固有かどうかを調べるために、さまざまなドメインにおける生成された要約の忠実度の空間的分布を分析します。主実験で使用したWikipediaデータセットに加えて、arXiv(Cohan et al., 2018)、PubMed(Cohan et al., 2018)、およびGovReport(Huang et al., 2021)データセットを追加して、さらなる評価を行います。
3.2 評価指標
忠実度
私たちは、要約の事実性を評価する際に大きな効果を示した原子事実に基づく評価指標を採用します(Min et al., 2023; Tang et al., 2024; Scirè et al., 2024; Jing et al., 2024; Wei et al., 2024; Yu et al., 2024)。
「si」 は、生成された要約文(S)の中の「i番目の文」です。各文「si」は、原子事実Aiに分解されます。原子事実は、さらに不要なものを除去するフィルタ処理が行われます。
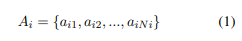
| 記号 | 意味 |
|---|---|
| si | 生成された要約文のうち、i番目の文 |
| Ai | 文 si に含まれる 原子事実 の集合 |
| aij | si から抽出された j番目の原子事実 |
| Ni | 文 si に含まれる原子事実の数 |
NLIモデルを使用して、各フィルタリングされた原子事実は、ソース文書D = {d1, …, dM}とペアワイズで比較されます。私たちは含意スコアのみを測定し、各原子事実にはその比較の中で最も高い含意スコアが割り当てられます。
NLIモデルとは?
以下はChatGPTに聞いた結果です。
NLIモデル(Natural Language Inference model)は、近年の言語処理タスクにおいて非常に重要な役割を果たしています。以下に詳しく、かつわかりやすく説明します。
🧠 NLIモデルとは?
✔️ NLI = Natural Language Inference(自然言語推論)
2つの文の間に論理的な関係があるかどうかを判断するAIモデルのことです。
💡 具体的に何をするの?
与えられるもの:
- 前提文(premise):元の情報
- 仮説文(hypothesis):そこから導けるかチェックしたい文
モデルが判断する3つの関係:
- Entailment(含意):前提から仮説が導き出せる
- Contradiction(矛盾):前提と仮説が矛盾している
- Neutral(中立):前提から仮説が導き出せるとも言えないが、矛盾もしていない
🧪 例で見てみよう!
✉️ 前提:
「富士山は日本で最も高い山です。」
📜 仮説:
A. 富士山は高い山である → ✅ Entailment
B. 富士山はアメリカにある → ❌ Contradiction
C. 富士山は観光地として人気がある → 🤔 Neutral
🔍 LLMや要約のfaithfulness評価にどう使われる?
今回の論文のような要約タスクでは:
- 要約から抽出した「atomic fact(小さな事実)」を仮説として、
- 元の文書の各文を前提として使い、
- NLIモデルで比較して、そのfactが元文書に「ちゃんと根拠があるか(entailment)」を調べます。
🛠️ どんなNLIモデルがある?
- 有名なモデルには以下のようなものがあります:
- RoBERTa(MNLI fine-tuned)
- DeBERTa-v3
- BART NLI
- Vectara Hallucination Evaluation Model(この論文でも使われている)
これらは事前学習された言語モデルを自然言語推論タスクに特化してfine-tuneしたものです。
✅ 要点まとめ
| 項目 | 内容 |
|---|---|
| 何をする? | 文と文の間の論理関係(含意・矛盾・中立)を判定 |
| どこで使う? | 要約・事実検証・QA・文章整合性評価など |
| 今回の論文では? | 要約文の事実(atomic fact)が元文書と一致するかをチェック |

最後に、文中のフィルタリングされた原子事実のセットに対する含意スコアの平均が、その文の忠実度スコアとして使用されます。
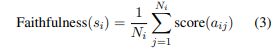
実験の詳細については、付録Bをご参照ください。
感度
忠実度スコアに加えて、生成された出力における位置的な不一致を分析するためのシンプルで効果的な指標を提案します。具体的には、各要約は5つの等しい長さのビンに分けられ、各ビン内の原子事実の平均忠実度スコアが計算されます。感度は、最後のビンの忠実度スコアと最初の4つのビンの平均との違いとして定義されます。感度の値が正であれば、最後で幻覚が発生する傾向があることを示し、負の値はそれとは逆であることを示します。感度が大きいほど、出力の最後での幻覚がより顕著であることを意味します。
3.3 最後に幻覚を見る
要約の後半部分は、ほとんどすべてのモデルにおいて、すべてのコンテキストと要約の長さにわたって最も低い忠実度を示しています。私たちは、Wikipediaデータセットにおいて、異なるモデルで生成されたショート要約とロング要約の位置的忠実度の不一致を、それぞれ異なる入力コンテキスト長に基づいて図2と図3で示します。図2に示すように、Mistralを除く3つのモデルで生成されたショート要約は、入力コンテキストの長さに関係なく、要約の後半の位置に向かって一貫して忠実度が低下する傾向があり、最も低い忠実度スコアは主に最後に観察されます。興味深いことに、生成された要約の位置的な不一致は、入力コンテキスト長によって顕著に影響されないことがわかりました。具体的には、要約の最後での忠実度の低下は、1Kと8Kのコンテキスト長の設定間でほぼ同じままです。
しかし、図3に示すように、ロング要約では「最後で幻覚が発生する」現象がさらに深刻になります。生成された要約の長さが増すにつれて、要約の後半に向かって忠実度スコアが継続的に低下し、最終的には8Kコンテキストから45文が生成されると、忠実度スコアは0.6を下回ります。
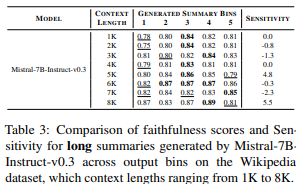
表2には、Llama3.1モデルで生成されたロング要約の感度結果を、表3にはMistralモデルの結果を報告します。結果に示されているように、Llama3.1によって生成された要約は、最後のビンで最も低い忠実度スコアを示す傾向があり、その結果、高い感度を示します。一方、Mistralモデルは、最初のビンで最も低い忠実度スコアを示すことが多く、感度はしばしば0未満になります。これらの対照的なパターンの根本的な原因については、セクション4で分析します。詳細な結果については付録Cをご参照ください。
要約の後半部分は、ほとんどすべてのデータセット、コンテキスト、および要約の長さにおいて一貫して最も低い忠実度を示しています。図4では、Llama3.1-8B-Instructモデルで生成されたロング要約の位置的忠実度不一致を、異なるデータセットにわたって示しています。結果に示されているように、「最後で幻覚が発生する」という傾向は、複数のドメインで一貫して観察されます。出力の長さが増すと、忠実度スコアは最終部分に向かって低下する傾向があり、特に生成された要約の長さが増すにつれて、後半部分の忠実度が継続的に低下します。特筆すべきことに、PubMedデータセットでは、8Kコンテキスト長で45文が生成されると忠実度スコアが0.5を下回ります。さまざまなデータセットでの追加の感度結果は、付録Dに報告されています。特筆すべきは、すべてのデータセットで計算された感度スコアが0未満にならなかったことです。
図2:
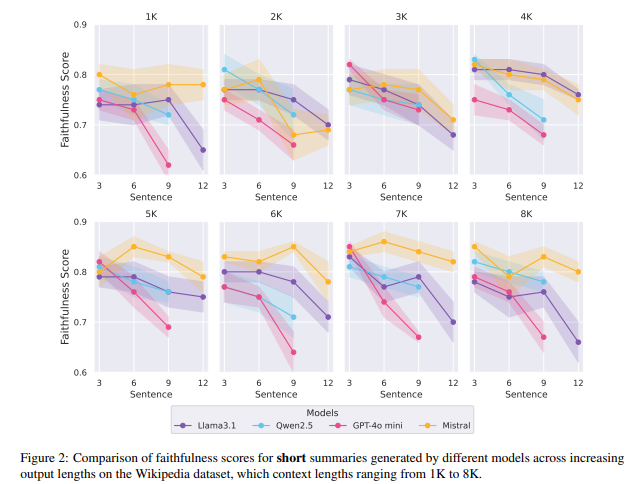
図3:
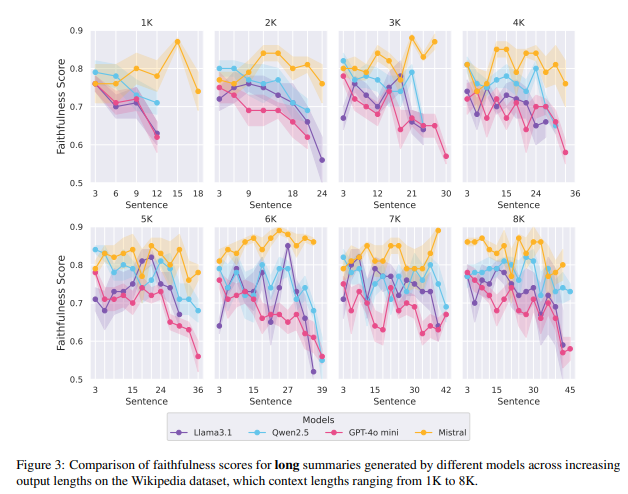
図4:
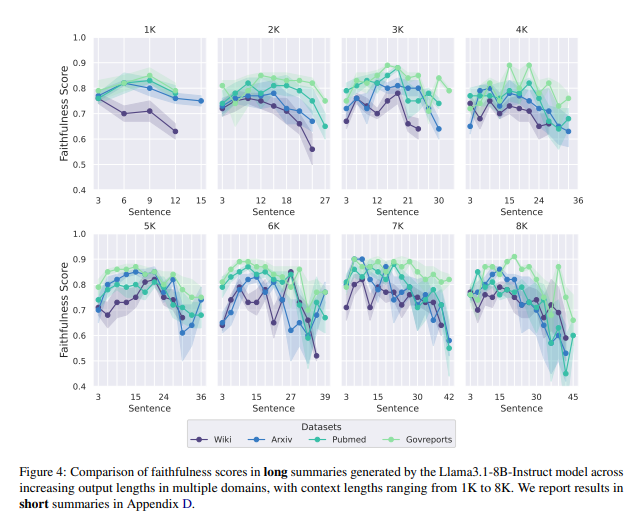
表2:
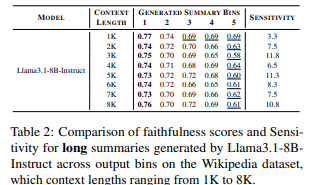
表3:
4 幻覚はなぜ最後によく起こるのか?
このセクションでは、「最後で幻覚が発生する」現象に寄与する根本的な要因を調査し、2つの主要な仮説を探ります。第一の仮説は、この現象を要約の固有の性質に起因させるもので、重要な情報は通常要約の最初に集中し、重要でない内容は後半に現れるとしています。第二の仮説は、LLMが長い出力を生成するにつれて、元の入力コンテキストよりも以前に生成したトークンにより多く注意を払うようになり、注意の分布に変化が生じるというものです。
4.1 要約は本質的か?
この仮説は、人間が書いた要約とモデルが生成した要約の固有の構造に基づいています。ほとんどの要約タスク、特にニュース、科学的文書、およびWikipediaスタイルの文書では、主なアイデアや重要な情報は通常、要約の最初に提示されます(Hermann et al., 2015; Narayan et al., 2018; Cohan et al., 2018)。この構造は、ソース文書でしばしば観察されるリードバイアスに似ており、文書の最初の部分に最も重要な内容が含まれています(Kim et al., 2019; Zhao et al., 2022; Ravaut et al., 2024)。これに動機づけられて、私たちの研究では、このような構造的バイアスが生成された出力における事実の一貫性の低下として現れるかどうかを調査しています。具体的には、人間が書いた参考要約とモデルが生成した要約の位置的忠実度スコアを比較し、忠実度の低下が要約の固有の構造の副産物であるのか、それともモデル特有の振る舞いであるのかを評価します。
リードバイパスとは?
以下はChatGPTの出力です。
論文内でも間接的に言及されていた 「リードバイアス(Lead Bias)」 について、詳しく、かつ研究的な視点からわかりやすく説明します。
📰 リードバイアス(Lead Bias)とは?
Lead(リード) = 記事や文書の冒頭部分(導入部)
Bias(バイアス) = 偏り
🔍 リードバイアスとは:
「元の文書では重要な情報が文の最初のほうに偏って出現する傾向」のことです。
🧠 どこでよく見られるの?
特に顕著なのは:
- ニュース記事
- 最初の数文で「いつ・どこで・誰が・何をしたか」を書く
- Wikipediaや学術要約
- 冒頭で概要・主張を先に伝える構成
📚 研究におけるリードバイアスの意味
多くの自動要約モデル(特に抽出的なもの)は、文書の最初の方の文だけを選んで要約しても、意外といいスコアが出ることがあります。
これはつまり:
「モデルはちゃんと考えて要約しているのではなく、文頭の文を選ぶだけで済んでしまう場合がある」
という、評価の盲点になります。
🧪 例:要約タスクにおける影響
- モデルが最初の3文だけ抜き出して要約を作ったら、ROUGEスコアは高かった。
- でも実は、中盤や後半に新情報や重要情報があっても、それが無視されてしまう。
これは、「モデルが本当に賢く要約しているのか?」を見誤る原因になります。
🧩 今回の論文との関係
この論文では、モデルが生成した要約の後半になるとfaithfulness(忠実性)が下がる、つまり誤情報が増えるという現象(Hallucinate at the Last)を指摘しています。
そこで議論として:
「それって、リードバイアスのせいで、重要情報が前に集中してるからでは?」という問いが出てきます。
論文ではその仮説を検証し、人間が書いた要約は後半も忠実なままなので、リードバイアスだけでは説明できないという結論を出しています。
✅ まとめ
| 用語 | 意味 |
|---|---|
| リードバイアス | 文書の冒頭に重要情報が集中している偏り。モデルの性能を「水増し」して見せる原因にも。 |
| 問題点 | モデルが深く考えず、最初の文だけ拾うような単純戦略でも高スコアが出てしまう |
| 本論文との関係 | 後半でhallucinationが増える理由が「リードバイアス」のせいか検証されている |
実験セットアップ
私たちは、CNNDMデータセットから人間が書いた参考要約を使用し、長い要約と約2Kトークンの入力コンテキストを持つ例を選択します。これらの参考要約を、セクション3.1で説明された指標を使用して評価したLlama3.1-8B-Instructモデルによって生成された要約と比較します。
CNNDMデータセットとは?
以下はChatGPTの出力です。
「CNNDMデータセット」は、要約(summarization)タスクにおいて非常によく使われる標準的なベンチマークデータセットです。研究でよく登場するので、知っておくととても役に立ちます。
🗂️ 正式名称と出所
- 正式名称:CNN/DailyMail データセット
- 作成元:アメリカのニュースメディア「CNN」と「Daily Mail(イギリス)」の記事をベースに構成
- 初出論文:Hermann et al. (2015), “Teaching Machines to Read and Comprehend”
📰 内容(どんなデータ?)
各データは:
- 本文(article):CNNやDailyMailの実際のニュース記事
- 要約(highlights):その記事に対して、人間(記者)が書いた要約文。通常は箇条書き(bullet形式)
例:
[Article]
A lion escaped from a zoo in San Diego on Friday evening...
[Highlights]
- A lion escaped from the zoo
- Police captured the lion within an hour
- No injuries reported
📏 データのサイズ
- 訓練用(train):約280,000件
- 検証用(validation):約13,000件
- テスト用(test):約11,000件
🔍 どんな研究で使われる?
- 抽出的要約(extractive summarization)
- 抽象的要約(abstractive summarization)
- 忠実性評価(faithfulness evaluation)
- Hallucination検出 など
この論文でも、人間が書いた要約(reference)とモデル生成要約を比較する際に使用されています。
🧠 このデータセットの利点と課題
| 利点 | 課題 |
|---|---|
| 実世界のニュースに基づいているため汎用性が高い | リードバイアスが強い(=冒頭部分だけ拾ってもそれなりに良い要約になる) |
| 要約は人手で作成されており信頼性が高い | 情報が断片的(bullet形式)で、文脈が弱いことも |
| データ量が多くLLMにも適している | やや古く、形式も単調なので限界もある |
✅ まとめ
| 項目 | 内容 |
|---|---|
| 名前 | CNN/DailyMail(CNNDM)データセット |
| 中身 | ニュース記事とその要約(ハイライト) |
| 用途 | 要約モデルの訓練・評価、faithfulness検証 |
| 特徴 | 人手による要約つきの大規模コーパス。リードバイアスが強いことで有名 |
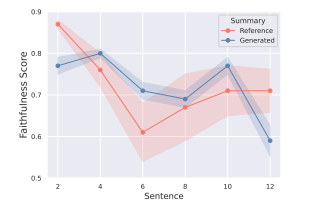
結果と分析
図5は、CNNDMデータセットからの人間が書いた参考要約とモデルが生成した要約の位置的忠実度の比較を示しており、出力長が増加するにつれて分析されています。結果に示されているように、参考要約は生成された要約とは異なるパターンを示します。生成された要約の忠実度スコアは最終セグメントで0.6を下回りますが、参考要約は中間付近で一時的に低下し、その後、最後に向かって回復します。この観察結果は、「最後で幻覚が発生する」現象が要約の固有の特徴だけに起因するわけではないことを示唆しています。
図5:
4.2 注意(Attention)は本質的なものか?
LLMに関する先行研究では、注意重みの分布が生成プロセスと密接に関連しており、出力の一貫性に影響を与えることが示されています(Dong et al., 2021; Zhang et al., 2024b)。最近の大規模視覚-言語モデル(LVLM)に関する研究では、生成されたテキストの後半部分で幻覚が頻繁に発生することが示唆されています(Liu et al., 2024a; Lee et al., 2024; Min et al., 2025)。この現象は、注意のシフトに起因するとされています。テキスト生成が進行するにつれて、注意重みが画像トークンよりも以前に生成されたテキストトークンにますます有利になるのです。この観察結果に触発されて、私たちはLLMにおいても同様の傾向が存在するかどうかを調査し、生成されたトークンへの注意重みが出力長の増加に伴ってどのように進化するかを分析します。
実験セットアップ
従来の研究が最初に生成されたトークンへの注意に焦点を当てているのとは異なり(Hsieh et al., 2024)、私たちは文レベルでの注意重みを計算します。さらに、全文を100トークンのチャンクに分割します。私たちの分析は、生成された出力の中で特に3つの位置に焦点を当てています:最初の文、中間の文、そして最後の文です。詳細については、付録Eをご参照ください。
結果と分析
図6は、文ごとの平均注意重みの可視化を示しています。結果に示されているように、「最後で幻覚が発生する」パターンを示したLlama3.1-8B-Instructモデルは、生成された要約の最後の文に対して、最初と中間の文に比べてほぼ4倍の注意を割り当てています。それに対して、Mistral-7B-Instruct-v0.3モデルは、3つの文位置に対して同様のレベルの注意を割り当てています。これらの結果は、以前に生成されたテキストに対する注意の増加が幻覚の可能性の高さと関連していることを示唆しています。さらに、ほとんどのモデル(Mistralを除く)では、出力長が増すにつれて注意が生成されたトークンにますます集中し、それが幻覚を増幅させることが観察されました。
図6:

5 最後の幻覚を和らげるには?
我々は、ラストで幻覚を見る現象をどのように解決できるかを調査する。そのために、4つの方法を適用する。
実験セットアップ
この実験では、Wikipediaデータセットに対して7Kトークンのコンテキスト長を使用して、4つの異なる方法で要約を生成します。ベースラインとして、Llama3.1-8B-Instructモデルによって生成された要約を使用します。比較のため、以下の4つの方法を評価します
BOOOOKSCORE
入力コンテキストをチャンクに分割し、各チャンクに対して個別に要約を生成した後、部分的な要約を統合する方法です。
MINFERENCE
疎な注意機構を使用して、長い入力シーケンスを効率的に処理する方法です。
LONGWRITER-LLAMA3.1-8B
長い出力のデータセットでファインチューニングされ、その後、DPO(Rafailov et al., 2023)を使用してさらに強化されたモデルです。
ADACAD
文脈を意識したデコーディングを使用して、生成中の事実の一貫性を強化する方法です。
実験の詳細については、付録Fをご参照ください。
結果と分析
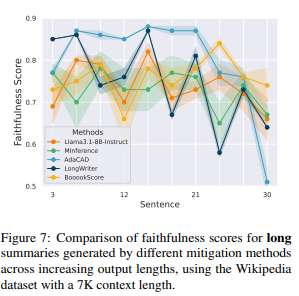
出力ビンごとの忠実度スコアと対応する感度結果は表4に、各方法の出力長の増加に伴う忠実度スコアは図7に報告しています。表4に示されているように、BOOOOKSCOREは最も低い感度(2.0)を達成しており、4つの方法の中で最もゼロに近い値を示しています。さらに、図7に示されるように、BOOOOKSCOREは特に30番目の文周辺で最高の忠実度を維持し、他の方法が要約の最後で観察される忠実度の急激な低下を回避しています。これらの結果は、各チャンクごとに要約を独立して生成し、その後統合することが「最後で幻覚が発生する」現象を軽減する効果的な戦略であることを示唆しています。しかし、BOOOOKSCOREはこの現象を軽減する一方で、生の長い入力から直接長いレスポンスを生成する問題を根本的に解決するわけではなく、代わりにチャンク分割と統合によって問題を分解しています。これにより、長いコンテキストから直接長文を生成する際にモデルが忠実度を維持できる方法を開発する必要性が今後の研究において強調されています。
表4:
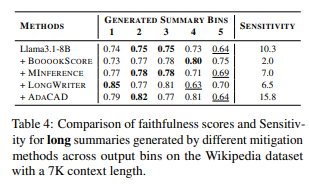
図7:
6 関連研究
LLMにおける幻覚の問題は、重要な研究分野となっています。先行研究では、生成されたテキストにおける事実の不整合を検出する方法(Chuang et al., 2024; Hu et al., 2024; Kim et al., 2024; Zhong and Litman, 2025)や、その発生を軽減するための戦略が提案されています。これらの戦略は通常、訓練(Zhang et al., 2023; Wan et al., 2023)、デコーディング(Shi et al., 2024; Wang et al., 2025)、またはプロンプティング(Zhou et al., 2023)の改善を通じて行われます。全体的な幻覚率を低減するには効果的ですが、これらの研究は通常、シーケンス内での誤りの分布については分析していません。
生成エラーにおける位置的バイアスの概念は、関連するドメインで観察されています。特に、大規模視覚-言語モデル(LVLM)に関する研究では、生成された画像のテキスト記述の後半に幻覚が増加する傾向があることが示されています(Liu et al., 2024a; Lee et al., 2024; Min et al., 2025)。
最近、いくつかの研究がLLMにおける長出力生成の探求を始めています(Wu et al., 2025b; Ye et al., 2025)。しかし、これらの研究は文脈に基づかない手続き的生成タスクに焦点を当てており、実際の要約シナリオにおける適用性に限界があります。複数文書要約に関する注目すべき研究は、私たちの発見と一致しています(Belém et al., 2025)。とはいえ、この研究は長い要約の生成における位置的コンテキストを意識した忠実度には言及していません。
私たちの研究は、LLMベースの長文書要約における幻覚の発生場所を初めて専用に調査したものであり、検出を超えて位置的パターン、根本的な原因、そして軽減戦略を明らかにすることを目指しています。
7 結論
私たちは、LLMベースの長いレスポンス生成、特に長文書要約における「最後で幻覚が発生する」現象を特定し、特徴付けました。私たちの発見は、幻覚が長い出力の後半に不均衡に増加し、このバイアスが長い要約でさらに強調されることを示しています。私たちは、その原因となる要素を調査し、ターゲットを絞った軽減戦略を探りました。私たちの研究は、LLMの忠実度における出力の時間的次元の重要性を浮き彫りにし、空間的に意識した生成技術に関する今後の研究を促進するものです。
制限事項
本研究では、主に対応するデータセットが望ましい長さの入力コンテキストを提供していたため、4つのドメインを調査しました。しかし、書籍、対話、映画の脚本、会議の議事録などのドメインについては調査できませんでした。書籍は長すぎるため除外され、他のドメインは適切な入力長さや十分なサンプルサイズを持つデータセットが不足していました。また、異なるサイズのモデルについても調査していません。
これらの制限にもかかわらず、本研究は長文生成、特に要約における比較的未開拓のドメインに関する今後の研究のための重要な基盤を提供すると考えています。
倫理声明
本研究は、Wikipedia、Arxiv、Pubmed、Govreport、CNNDMなどの公開されているデータセットを活用し、LLMにおける長文生成を分析しています。すべての実験は、モデルおよびデータセット間で一貫性と再現性のある方法で実施され、データや結果の操作や省略は一切行われていません。私たちは、「最後で幻覚が発生する」現象を調査しました。この現象は、長いコンテキストを意識した要約モデルにおいて、要約の最後の部分で幻覚的なコンテンツが生成される傾向です。この問題に注目することで、私たちの研究は、LLMによって生成された要約の信頼性と事実の一貫性を高めるための継続的な努力に貢献しています。
謝辞
本研究を進めるにあたり、多くの方々の支援と協力をいただきました。まず、使用したデータセットを提供してくださった研究者の皆様に感謝いたします。特に、Wikipedia、Arxiv、Pubmed、Govreport、CNNDMといった公開データセットの利用が、本研究の基盤となりました。
また、本研究に関わるすべての技術的および理論的な議論において貴重な意見をいただいた同僚や研究者の皆様にも深く感謝申し上げます。さらに、実験設計と結果の分析においてサポートしてくださったチームメンバーにも感謝いたします。
最後に、AI技術とその応用における倫理的課題に関する議論を提供してくださった専門家の方々にも、貴重なご助言をいただきありがとうございました。
得られた知見
① Hallucination(誤情報)は出力の最後に集中する
- 長文要約タスクにおいて、出力文の後半に事実誤り(hallucination)が偏って現れる傾向がある。
- この現象を著者たちは 「Hallucinate at the Last」 と名付けている。
- 全てのモデル・全ての文書ドメインでこの傾向が確認された(Wikipedia, arXiv, PubMed, GovReport)。
② 要約の長さが増えるほど、後半のfaithfulnessが急激に低下する
- 出力文が長くなる(例:45文)ほど、後半のfaithfulnessスコアが0.6以下に落ちるケースが多発。
- 特にLLama3.1系のモデルで顕著だった。
③ 入力文書の長さ(context length)は誤情報の位置傾向にほぼ影響しない
- 1K〜8Kトークンまで文書長を変えても、「最後で誤情報が増える」傾向自体はほとんど変わらなかった。
④ この現象は「リードバイアス」だけでは説明できない
- 人間が書いた要約(CNNDMのreference summary)では、後半のfaithfulnessはそれほど下がらなかった。
- よって、「最初に大事なことを書く文化(リードバイアス)」だけが原因ではない。
⑤ Attentionの偏りが一因かもしれない
- 図6の解析より、Llama3.1など一部モデルでは後半の文ほど、元の文書ではなく自分の出力に注意を向ける傾向がある。
- 自己ループ的な生成が誤情報を生みやすいと示唆。
⑥ Mistralモデルは比較的hallucinationが少ない
- Mistral-7B-Instructは、attentionが安定しており、後半でもfaithfulnessスコアの低下が小さい。
- 特定モデルの設計・訓練により誤情報耐性に差が出る可能性がある。
⑦ Mitigation(軽減策)もいくつか効果を示した
4つの手法を比較し、以下のような傾向が示された(図7とTable 4):
| 手法 | 効果・傾向 |
|---|---|
| BOOOOKSCORE | 入力をチャンク分割して要約 → 誤情報が大幅減少 |
| MINFERENCE | sparse attentionにより効率化+改善 |
| LONGWRITER | 長文生成に特化した学習 → 中程度の改善 |
| ADACAD | context-aware decoding → 一部効果はあるが不安定 |
※BOOOOKSCOREが最も安定したfaithfulnessを実現。
⑧ 従来研究との違い:出力側の構造的hallucinationに注目した初の研究
- 多くの既存研究は「入力が長くなるとモデルが混乱する(Lost in the Middle)」に注目。
- 本研究は「出力側における誤情報の構造的分布」に焦点を当てた点が新しい。
⑨ 今後の課題と方向性
- 単なるチャンク分割(BOOOOKSCORE)では「直接長文生成」はできない → 長文でもfaithfulなend-to-end生成能力が求められる。
- attentionの構造制御や、出力文の検証再構成(post-hoc validation)などが今後の研究トピック。


コメント